
Part 1: What is openEHR? (and why should you care?)
Let’s start with the basics: the pronunciation 😅…. In order to learn and talk about openEHR, you should know how to pronounce it. It’s “open-air”, as in free outdoor space where you can breathe. But some people also call it open E-H-R. Either is fine!
Now, what is it exactly?
openEHR isn’t an app or a single software product. It’s an open standard for how health data should be structured, stored and preserved, in order to ensure that data remains meaningful and usable for decades, no matter what system or vendor you use.
The problem: when software and data are mixed
Most healthcare systems today mix clinical logic (the rules for a diagnosis, or the fields for a blood pressure reading, for example) directly into their software’s codebase, and this creates a massive problem: when the software changes or gets replaced, the meaning of the data often breaks or is lost.
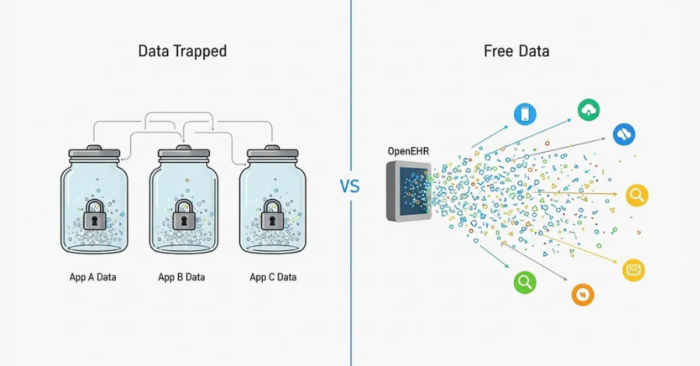
The openEHR solution: separation of concerns
openEHR fixes this issue with a simple but revolutionary idea: by separating the clinical knowledge from the software logic.
Clinicians and informaticians define what the data means (using ‘Archetypes’ – standardised models for clinical concepts, and ‘Templates’ – combinations of those archetypes for real-world use cases) and developers focus on how the data is stored and displayed. This separation is the key, since it makes health data clinically meaningful, vendor-neutral, and, most importantly, future-proof. This means that whether you’re in Lagos or London, now or 10, 20, 50 years from now, “blood pressure” means the exact same thing in every openEHR system.
Why this separation is a game-changer
The lifespan of most enterprise software is 7 to 12 years. After that, it gets deprecated, rebuilt or merged. That’s fine; technology is supposed to evolve, but what’s not fine is losing the clinical data that has been collected over those years. This is the core reasoning behind openEHR. It advocates for a complete separation of data from applications. In simple terms: your data shouldn’t “belong” to your software; your software should simply “use” the data.
By modeling health data using openEHR standards, we ensure that even when the application changes, the data remains reusable, interoperable, intact, and ready for the next generation of systems. That’s why openEHR emphasises building the data layer first, not as an afterthought, but as the foundation. Software comes and goes, but health data should live forever.
Part 2: The big idea: the “Lego model” explained
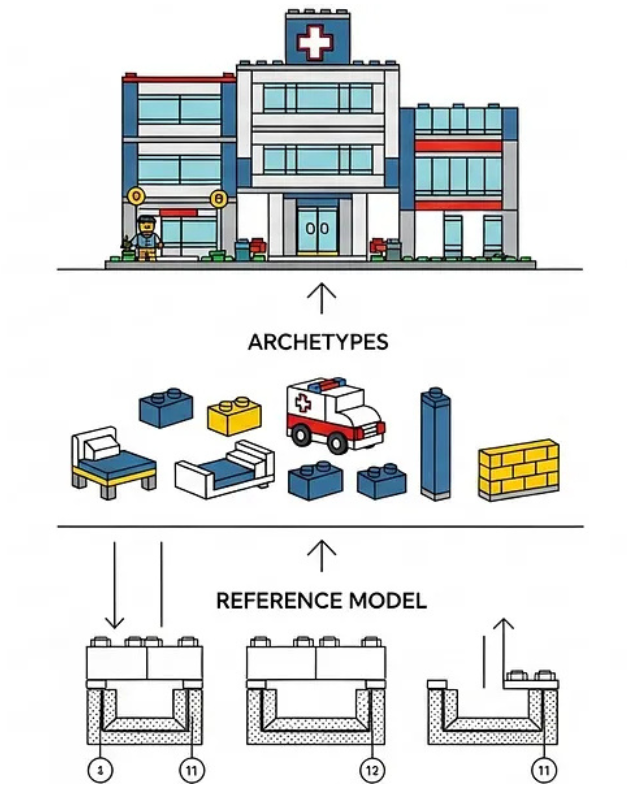
You’ll hear that openEHR has three building blocks: we’ve touched on Archetypes and Templates already, but there’s also the Reference Model. So, what do those terms mean, and how do they work together?
Let’s use an example we all understand: Lego. It’s the most popular and, frankly, fun way to explain the standard….
The Reference Model: The “Lego Rules”
Imagine you’re sitting on the floor with a big box of Lego bricks (or “Legos” – it’s up to you). Before you build anything, you’ll notice that no matter the colour, shape, or size, every single piece connects perfectly with every other one. That’s because Lego has a universal rule; a standard for how its connectors (the little studs and tubes) fit together.
That rulebook, the underlying structure that defines how every piece connects, is the same as the openEHR Reference Model: it’s the technical foundation that defines how all data pieces fit, how they relate to one another and what they can contain. It’s the reason every “block” of data you create can fit into any other, anywhere, and at any time.
Archetypes: “pre-built Lego sets”
Now, let’s say you’ve got one of those fancy Lego sets: a hospital set. Inside the box, you find smaller, pre-built structures: a patient bed, an ambulance, a mini X-ray machine. These are the Archetypes. They are reusable, clinically meaningful units; models for concepts like “blood pressure,” “lab result,” or “allergy.” Every Archetype follows the same universal Lego rules (the Reference Model), but each one brings a distinct clinical concept to life. In our analogy, they are ‘pre-built’ ready-made “concept-bricks” that you can pick up and use in any build.
Templates: the “final creation”
It’s time to construct your masterpiece: the full hospital. You take your Archetypes (the beds, rooms, equipment) and arrange them into one large structure that represents your specific use case.
This is your Template: the real-world implementation. A Template decides which Archetypes to include, which optional parts to ignore, and how they all come together to represent a clinical workflow or document, like an “antenatal visit form” or a “discharge summary.”
So, in essence:
The Reference Model is the universal Lego system, the rules that make all the pieces fit together.
The Archetypes are the individual bricks and pre-built sets, the reusable, meaningful pieces.
The Template is the final structure you build, your finished product for a specific purpose.
And here’s the good part: even if you decide to take your hospital apart and build something else, your Lego pieces remain perfectly intact and reusable. In the same way, if you take your application apart and decide to build a new one, your data remains intact and you can rebuild, reimagine, and reuse it again in another project, forever.
Part 3: The core architecture: the 3 layers of openEHR
Now you understand the “Lego Model” as an analogy, let’s look at the formal definitions of those three layers, because each one is quietly brilliant within the architecture.
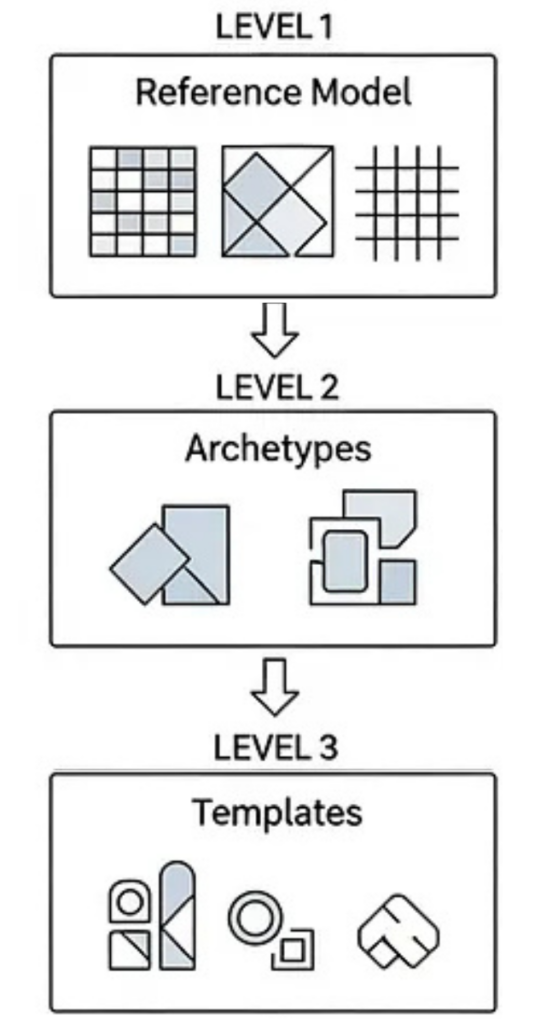
The Reference Model (The “Rules” of the Lego System)
In our analogy, we said that no matter what you create, everything connects perfectly, because Lego follows a universal rule: every piece must fit into every other. That rulebook is the Reference Model (RM). The RM defines the technical “grammar” of health data: it decides what can exist and how each part connects to the next.What it doesn’t describe is the clinical meaning (like “blood pressure”); it only defines the structure that makes meaning possible.
It provides the building blocks:
- A COMPOSITION is a full clinical document (like a discharge summary).
- A SECTION organises that document.
- An ENTRY records a clinical statement (what was observed, instructed, or done).
- A CLUSTER groups related data (like systolic and diastolic).
- And an ELEMENT is the smallest data item (e.g., Systolic BP = 120 mmHg).
These aren’t just random names; they are carefully engineered so that every piece of health data fits together. Remember – it’s the Reference Model that makes your data future-proof.
Archetypes (the “universal bricks”)
If the Reference Model (RM) is the rulebook, it’s the Archetypes (AT) that provide the meaning. Think back to our hospital Lego set. Inside, you found pre-built units: a patient bed, a monitor, a nurse’s station. That’s what Archetypes are: reusable models of real-world clinical concepts, all built using the rules of the Reference Model.
An archetype says:
“Here’s what blood pressure looks like: it must have systolic, diastolic, position, and time.”
“Here’s what an allergy record must contain: substance, reaction, severity, and status.”
Each archetype captures one clear piece of clinical knowledge. They are standardised and shareable. Clinicians and informaticians collaborate to publish them on the Clinical Knowledge Manager (CKM), a global library of archetypes.
This means if one hospital here in Lagos records “blood pressure” and another in London does too, and both use the same archetype, their data is instantly comparable and interoperable.
Templates (The “Instruction Manual”)
We now have our rules (the RM) and our meaningful bricks (Archetypes). But real-world forms and workflows aren’t just one concept. They combine many and that’s where Templates come in.
A template is the final, practical implementation. It’s the “container” that assembles multiple archetypes to reflect a specific clinical document or data entry form.
For example, an “antenatal visit template” might include:
- A “Blood Pressure” archetype
- A “Urinalysis” archetype
- A “Fetal Heart Rate” archetype
- A “Clinical Notes” archetype
The template defines which archetypes to include, which optional fields to hide, and how they all appear together in a single, usable form. Once designed, this template is what developers use to generate the actual data-entry forms, ensuring the end product is standardised for everyone’s usage.
In short:
- Reference Model = Defines how data fits.
- Archetypes = Define what data means.
- Templates = Define how data is used in context.
Part 4: Conclusion: a future-proof foundation
So, what’s the big takeaway?
The openEHR approach, which is this separation of “rules,” “concepts,” and “use cases”, isn’t just a technical detail. It’s a completely new philosophy for health data.
Instead of your data being locked away in vendor-specific silos, openEHR turns it into a liquid, reusable, and permanent asset. The “Lego bricks” of your patient’s health story can be used and re-used by any application, now and in the future.
This model puts clinicians and informaticians – the people who actually understand health – in charge of what clinical data means. The software’s job is simply to store, retrieve, and display it.
This is how you build a data layer that will outlive any single EMR, app or vendor. It is the foundation for a truly future-proof and interoperable digital health ecosystem.
Understanding the “what” and “why” of openEHR is the essential first step, but the next logical question quickly becomes how to put that knowledge into practice and actually start using it. This means learning how to take a real-world clinical form, identify the appropriate Archetypes, and combine them into a working Template, a practical and hands-on activity known as clinical data modeling. Now that you understand the building blocks and how they fit together, your next step is to learn how to think and work like the architect, so do continue your journey with my next blog post. Coming soon!
Anselm Iwuanyanwu is an Interoperability Lead and software engineer passionate about future-proof health data. With a unique background in both clinical pharmacy and full-stack development, he specialises in designing and building scalable systems using openEHR and FHIR standards. He is dedicated to advancing semantic interoperability in the global digital health landscape. Follow him on Linkedin
Leave a Reply