Veratech participated in INFOBANCO project promoting openEHR
Industry News | July 13, 2023, 11:22 a.m.
Sharing results of the INFOBANCO project, developed between April 2022 and June 2023 for the Madrid Health Service, Spain. Industry Partner, VeraTech for Health had the privilege of participating in it from its initial concept to its final implementation, encouraging the adoption of openEHR and the archetype modeling methodology.
INFOBANCO is the result of a Public Procurement of Innovation project with the aim of building a regional data platform for health research. This platform is intended to provide services to clinicians, managers, and researchers, making it possible to combine data from multiple sources. It is equipped with tools for data governance, collection, transformation, interrogation, visualization, and analysis to obtain knowledge and to support decision making.
The architecture of the INFOBANCO platform:
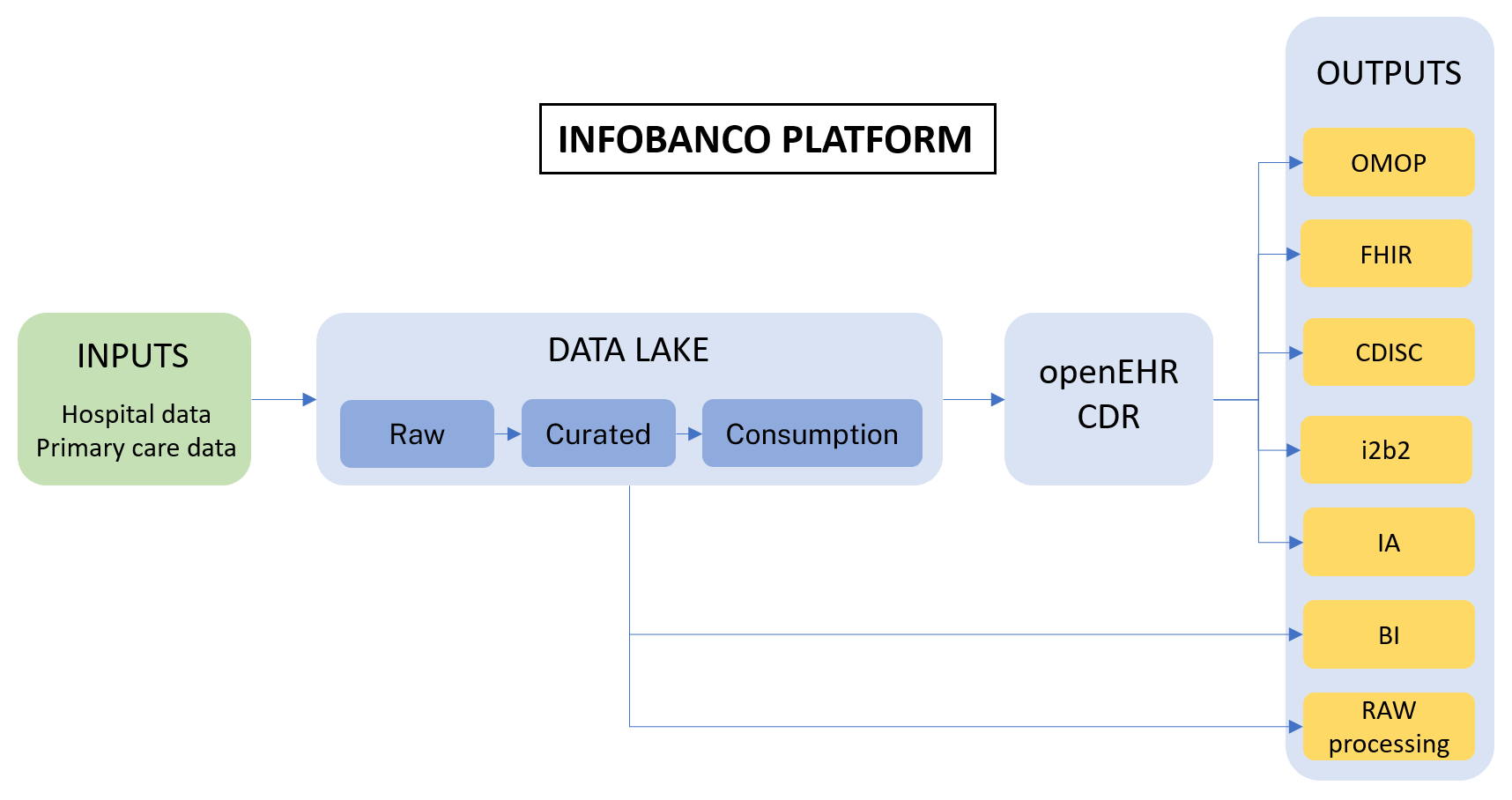
The innovative idea behind this architecture is to put an openEHR CDR in the center of a research platform, and to use it as the source for transformations of data (ETL processes) to other health data standards commonly used in the clinical research field (OMOP CDM, HL7 FHIR, CDISC ODM, i2b2). The hypothesis for this work was that the openEHR reference model and archetypes provide the most complete set of information (both health information and context information) to feed any other information model used by other standards.
Components of the platform:
- Inputs. Two different information systems have been integrated, including the EHR information from Hospital 12 de octubre and EHR information from the Primary Care area.
- Data lake. A first repository for raw data integration, facilitating a single entry point to process it. This data lake offers data in multiple layers: raw (data as is in its origin), curated (basic normalization, such as date or number formats), and consumption (classification/organization of data according to its domain).
- openEHR CDR. Data from the data lake has been normalized following openEHR archetypes and templates. Initially, only data covered by existing archetypes and required by the output formats has been included in the openEHR CDR. This CDR is built using the Better platform.
- Standard outputs. ETL processes have been implemented to convert openEHR data to other standard formats. The usual pathway has been the selection of relevant data for each output using AQL first, and then the implementation of data transformations using the most adequate technology in each case: Python, Java, Pentaho.
- Non-standard outputs. Some use cases required information that has not yet been included in the openEHR CDR (mostly data not covered by existing archetypes or internal management data from the input systems). In those cases, for example to build a BI control panel, data can still be accessed directly from the data lake.
The tasks of the project did not include any specific archetype modeling activity. Only templates were created using already existing archetypes. At this stage, more than 35 existing archetypes from the CKM were used to build 21 templates representing data such as Demographics, Encounters, Health problems, Medication administration, Immunizations, Alerts, Phenotype report, Genomic report, Family history, etc.
By the end of June 2023, the platform has been completed and the project has finished. A first set of 100.000 patients have been loaded into the platform, with the intention of loading the 450.000 patients of Hospital 12 de octubre in the following months, and up to the 6.5 million patients of the Madrid region in the foreseen future.
VeraTech gives thanks to the collaboration of the organisations below, who made this project possible.
- Hospital 12 de octubre, Madrid
- Área de Atención Primaria, Madrid
- Veratech for health
- NTT Data Spain
- RHEA Group
- Better
- European Union, European Regional Development Fund (ERDF)
- Ministerio de Sanidad de España
- Consejería de Sanidad de la Comunidad de Madrid
More information:
https://www.youtube.com/watch?v=qQBQ7kUzo6M
https://cpisanidadcm.org/infobanco/?lang=en
>> Back to Industry News